Vue 系列(二):谈谈编译器

在上一篇文章中,我们对 Vue 进行了简单地了解,梳理出了如上图所示的流程,在后面的文章中,我们将会以这个流程为主线对 Vue 进行详细地介绍,本篇我们将介绍 Vue 中的模板编译器。
编译器做了什么?
其实在上一篇文章中,我们就提及了编译器,只不过当时介绍的是编译器会把模板代码转换为虚拟DOM,其实只说对了一半。其实,编译器还会对虚拟DOM进行进一步处理,最终会把模板内容编译成渲染函数。
下面两段代码其实是等价的,编译器的作用就是把模板代码编译为渲染函数。
<template>
<div>
<p>Text1</p>
<p>Text2</p>
</div>
</template>
import { h } from "vue";
function render() {
return h("div", [h("p", "Text1"), h("p", "Text2")]);
}
下面就是我们实现的一个简单的编译器,可以在第一个文本框中输入 <div><p>Text1</p><p>Text2</p></div>,然后点击 Compile 按钮,可以看到转换后的渲染函数的代码与我们上面提供的一样。注:该编译器只支持简单的DOM,暂不支持属性。
GPL 和 DSL
在具体介绍编译器之前,我们得先了解两个概念:GPL 和 DSL:
- GPL(General Purpose Language):通用途语言
指被设计为各种应用领域服务的编程语言。通用途语言不含有为特定应用领域设计的结构,比如:Java、JavaScript、Scala 等等。
- DSL(Domain Specific Language):领域特定语言
专为特定领域所设计的语言,表达能力不如 GPL。(用表达能力上的妥协换取某一领域内的高效),比如:JSON、SQL、HTML、CSS 等等。Vue 的模板也是一种 DSL。
什么是编译器?
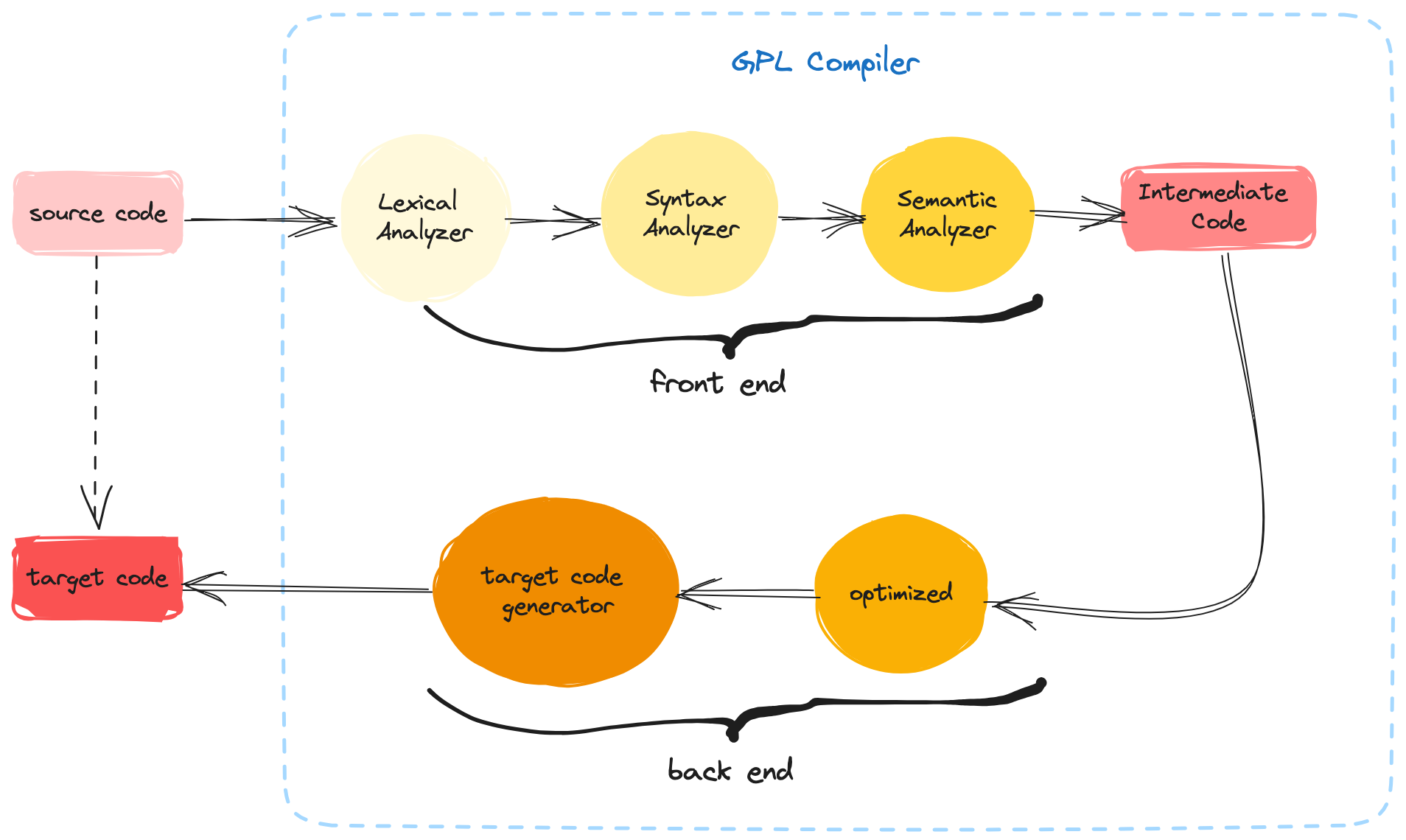
上图展示了一个完整的编译流程,源代码(source code)通过编译器(compiler)处理之后,最终生成目标代码(target code)。编译器的编译过程通常为如下几个步骤:词法(lexical)分析、语法(syntax)分析、语义(semantic)分析、生成中间代码(intermediate code)、优化(optimized)、目标代码生成器处理,最终生成目标代码(target code)。
我们要实现 Vue 模板的编译器,就可以参考上面的流程:
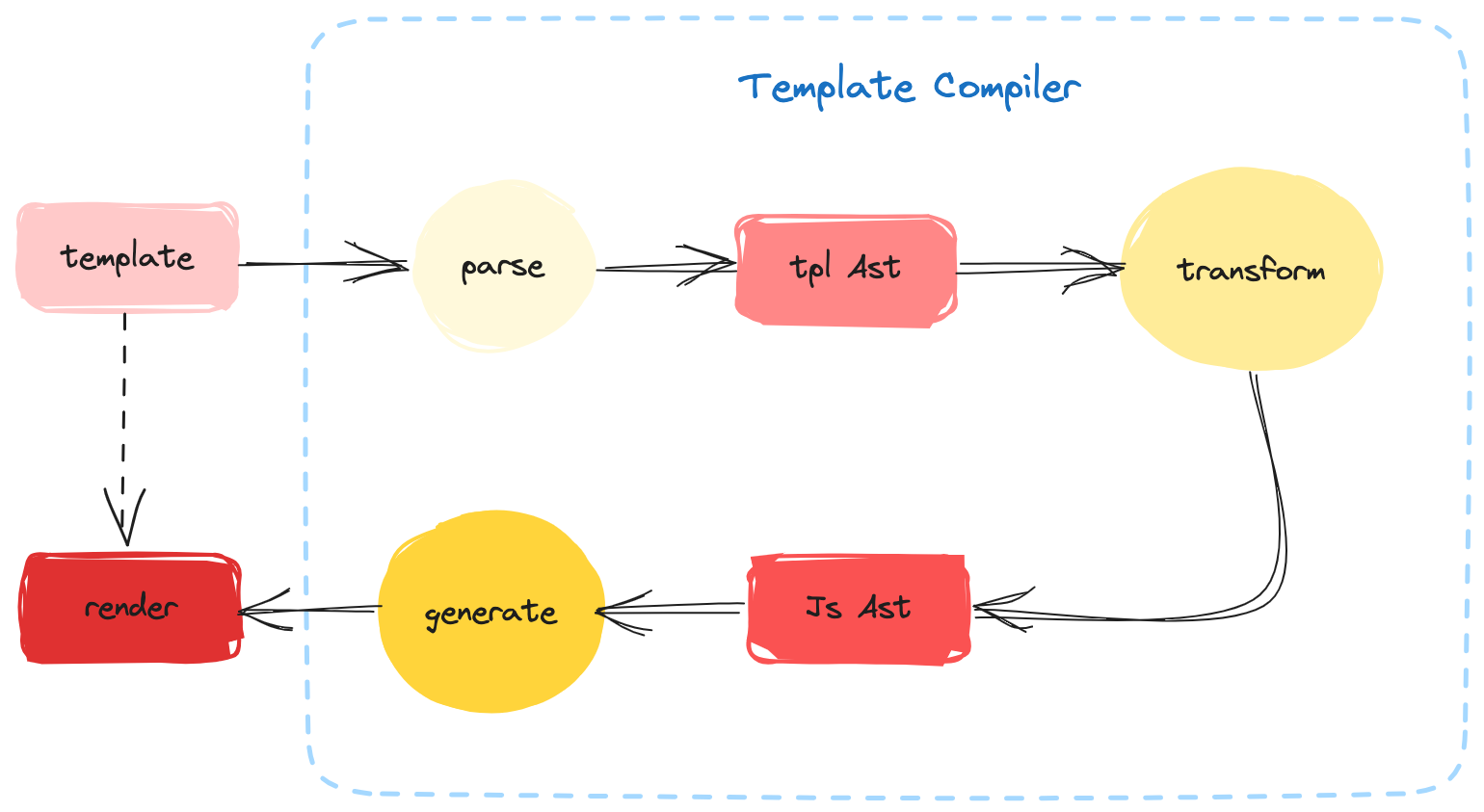
可以看到,我们所要实现编译器的流程与上面有一些不同。我们的源代码为前文提到过的 Vue 模板代码,目标代码为可以在浏览器或其他平台能运行的 JavaScript 代码。在编译的过程中,我们首先通过 parse 生成 tpl AST,然后通过 transform 生成 js AST,最后通过 generate 生成目标代码,也就是渲染函数。
那么根据上面的流程,我们可以先写出如下代码:
编译器伪代码
export const compiler = (template: string) => {
// parse template to template AST
const tplAst = parse(template);
// transform template AST to JavaScript AST
const jsAst = transform(tplAst);
// generate render code
const render = generate(jsAst);
return render;
}
通过前面的介绍,我们知道其实编译器就是一段程序,这段程序的作用就是将一种语言翻译成另一种语言。 简单说来就是字符串的转换[狗头保命]。
接下来我们将一步一步实现上面代码中所定义的方法,最终完成一个简单的编译器。
解析器
通过上面的介绍,我们可以知道,模板编译的第一步就是将模板代码解析为模板AST,如下图所示:
模板 AST
AST 就是 Abstract Syntax Tree,抽象语法树。模板AST就是用来描述模板的抽象语法树,举个例子:
<template>
<div>
<p>Text1</p>
<p>Text2</p>
</div>
</template>
上面就是一段模板代码,这段代码会被编译为如下AST:
模板 AST
{
"type": "ROOT", // root node
"children": [
{
"type": "ELEMENT", // tag/element node
"tag": "div",
"children": [
{
"type": "ELEMENT", // tag/element node
"tag": "p",
"children": [
{
"type": "TEXT", // text node
"content": "Text1"
}
]
},
{
"type": "ELEMENT", // tag/element node
"tag": "p"
"children": [
{
"type": "TEXT", // text node
"content": "Text2"
}
]
}
]
}
]
}
可以看到模板代码与模板AST的结构其实是一样的,都为树形结构,如下图所示:
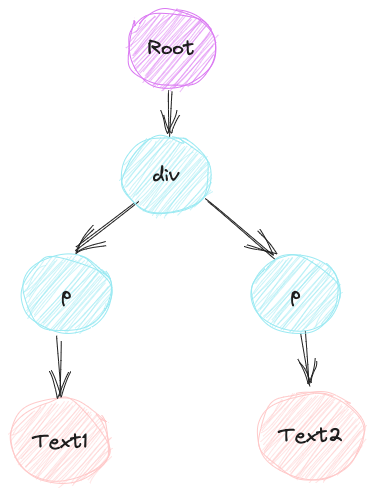
那么解析器的作用就是将模板代码解析为上面的 JavaScript 对象,也就是上一篇文章中所提到的 虚拟DOM。那么我们将从何处入手来进行模板的解析呢?
从 HTML 解析中找点灵感
我们知道,解析器的入参其实是字符串模板,解析器会逐个读取字符串模板的中的字符,然后将这些字符分割为一个一个的 token,token 可以理解为词法记号,以上面为例,解析器会将上面的模板代码分割为:div>、<p>、Text1······,那么解析器的这样去分割的依据是什么,其实就是通过切换一个一个的状态,不同的状态下对应不同的分割规则,那我们该如何确定这些状态呢?
我们知道 Vue 的模板其实是类似 HTML 的,而浏览器其实是会对 HTML 文本进行解析的,那么它是如何做的呢? 我们可以从WHATWG获得一些灵感。
WHATWG(Web Hypertext Application Technology Working Group):网页超文本应用技术工作小组,在该网站中定义了 HTML 的解析规范。这里我们不详细介绍这些规范和方法,因为要解析完整的 HTML 文本是比较复杂的。通过阅读该规范,我们发现 HTML 解析器在解析不同标签的时候会切换不同的文本模式(这里的模式就是状态):
- 在解析一般的标签时,比如:
<p>、<div>,会进入 DATA 模式
该模式下解析器会解析标签元素
- 当遇到
<textarea>、<title>,会进入 RCDATA 模式
该模式下无法识别标签元素,标签元素会被解析成文本,比如我们上面给出的编译器demo,就是通过文本框来实现,在文本框中我们输入的标签都会被解析成文本
- 当遇到
<style>、<iframe>等标签时,会进入 RAWTEXT 模式
该模式下,所有的字符都会被解析成文本。
有限状态自动机
通过前面的介绍,我们知道解析器在解析标签时,就是通过切换不同的状态来选择相应的规则,从而实现对模板的解析。这里的状态是有限个的,随着逐个字符的读取,解析器会自动切换不同的状态,这就是有限状态自动机。我们先来看看解析 Vue 模板需要多少种状态:
<template>
<div>
<p>Element node</p>
<textarea>RCDATA</textarea>
<style>
RAWTEXT
</style>
{{ Interpolation }}
Text
<!-- comment -->
</div>
</template>
上面列举了常见的几种文本:
一般的标签元素,对应 DATA 模式:
<div>、<p>RCDATA 模式下的标签元素:
<textarea>RAWTEXT 模式下的标签元素:
<style>插值:
{{ }}文本:
Text注释:
<!-- -->
根据上述的这些文本我们可以画出如下状态转换图:
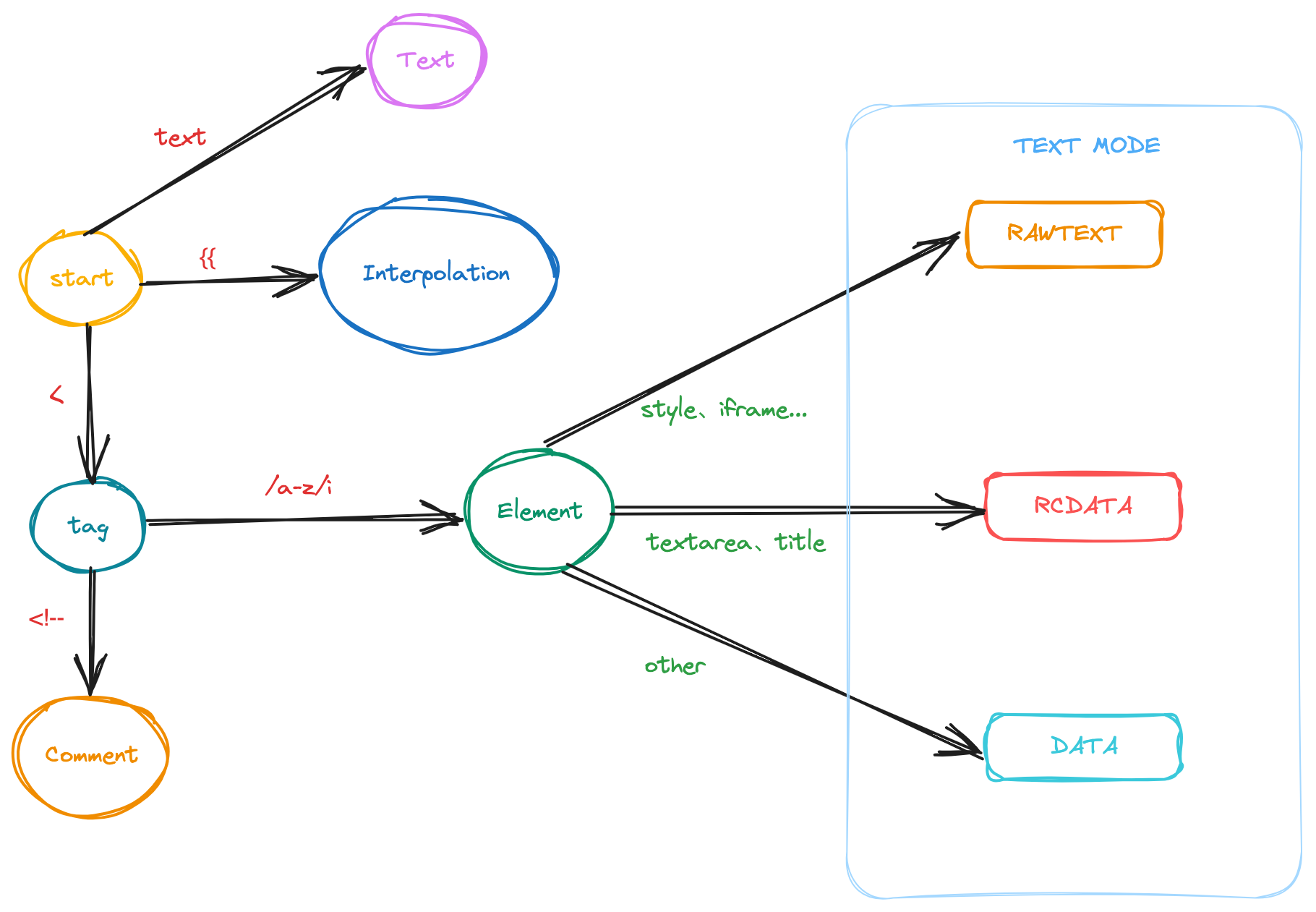
通过该状态图,我们可以画出如下流程图:
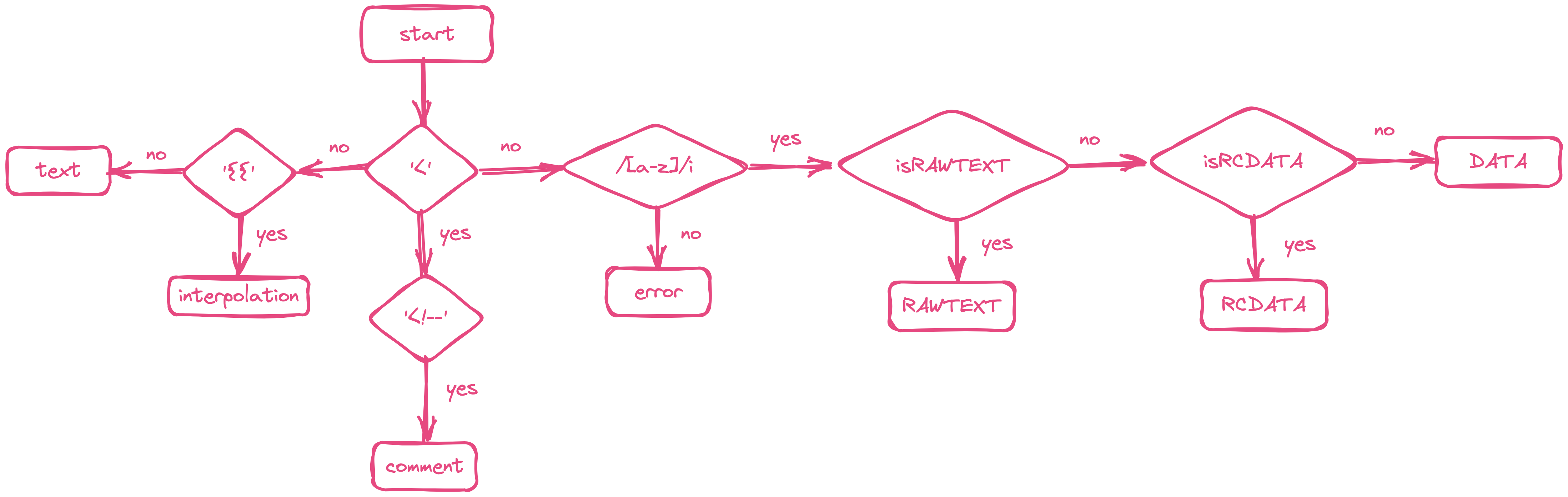
接下来我们就可以开始一步一步实现解析器了
定义模板AST
我们的解析器最终会将模板字符串解析为模板AST,那么我们先来定义一下模板AST的数据结构:
定义模板AST数据结构
export enum TYPE {
ROOT = "ROOT", // 根节点
ELEMENT = "ELEMENT", // 标签节点
COMMENT = "COMMENT", // 注释
TEXT = "TEXT", // 文本
INTERPOLATION = "INTERPOLATION", // 插值
EXPRESSION = "EXPRESSION", // 表达式
ATTRIBUTE = "ATTRIBUTE", // 属性
DIRECTIVE = "DIRECTIVE" // 指令
}
export interface TplAst {
type: TYPE, // 类型
tag?: string, // 标签名
isSelfClosing?: boolean, // 是否为自闭合
props?: Array<Props>, // 属性
content?: string | Content, // 内容,文本和表达式共用content
children?: Array<TplAst>, // 子节点
jsNode?: JsAst, // 后续转换为jsAST的时候使用
}
// 属性
export interface Props {
type: TYPE.ATTRIBUTE | TYPE.DIRECTIVE, // 属性的类型
name: string, // 属性名称
value: string, // 属性值
}
// 当节点类型为表达式时的内容
export interface Content {
type: TYPE.EXPRESSION,
content: string,
}
定义完模板AST的数据结构之后我们就可以写出解析器的代码了:
解析器代码
export const parse = (template: string): TplAst => {
// 上下文对象
const context = new Context(str);
const { consumeSpace } = context;
consumeSpace();
// 解析节点,该方法会返回解析之后的子节点
// 第一个参数为上下文对象,第二个参数为父级节点构成的节点栈,初始时为空数组
const nodes = parseChildren(context, []);
// 解析器返回根节点
return {
type: TYPE.ROOT,
children: nodes
}
}
通过代码我们可以发现,其实整个解析器的实现流程就是实现下面三步:

那接下来我们就各个击破!
上下文对象 Context
上下文对象其实不是一个陌生的概念,我们在编写复杂的转换函数时,通常需要定义一个上下文对象来维护全局的共享数据,比如当前解析器的状态、当前解析的文本等等。
定义上下文对象
export enum MODE {
DATA,
RCDATA,
RAWTEXT,
}
export class Context {
source: string; // 当前正在解析的文本
mode: MODE; // 解析器处于什么模式
// 构造函数,上下文对象中的初始mode为DATA
constructor(source: string, mode = MODE.DATA) {
this.source = source;
this.mode = mode;
}
// 消费字符
consume = (num: number) => {
this.source = this.source.slice(num);
}
// 消费空白字符
consumeSpace = () => {
const match = /^[\t\r\n\f\s ]*/.exec(this.source);
if (match) {
this.consume(match[0].length);
}
}
}
在上下文对象中,我们还定义了两个内部方法,consume 和 consumeSpace ,当我们解析模板字符串的时候,需要对模板字符串进行消费,即:删掉已经解析过的字符串。
解析子节点
当定义好上下文对象之后,我们就要开始实现对子节点的解析了,可以看到,解析子节点是整个解析器的核心。我们可以根据上面画过的流程图来写出解析子节点的代码:
解析子节点
// 子节点解析
// 第一个参数为上下文对象
// 第二个参数为祖先节点栈
export const parseChildren = (context: Context, ancestors: Array<TplAst>): Array<TplAst> => {
// 用来存储子节点的数组
const nodes: Array<TplAst> = [];
// 循环解析模板字符串
while(!isEnd(context, ancestors)) {
// 定义当前节点,初始为undefinded
let node;
// DATA 模式和 RCDATA 模式下支持标签和插值节点的解析
if (context.mode === MODE.DATA || context.mode === MODE.RCDATA) {
const { mode, source } = context;
// 解析标签
if (mode === MODE.DATA && context.source[0] === '<') {
if (source[1] === '!') {
if (source.startsWith('<!--')) {
// 解析注释节点
node = parseComment(context);
}
} else if (source[1] === '/') {
// 无效的结束标签
console.error('无效的结束标签');
continue;
} else if (/[a-z]/i.test(source[1])) {
// 解析标签节点
node = parseElement(context, ancestors);
}
} else if (source.startsWith('{{')) {
// 解析插值节点
node = parseInterpolation(context);
}
}
// 没有通过上面的代码进行解析,说明是文本节点
if (!node) {
// 解析文本节点
node = parseText(context);
}
// 解析完成的节点添加到节点数组中去
nodes.push(node);
}
// 返回子节点所组成的数组
return nodes;
}
通过上面的代码以及前文的分析,我们知道,parseChildren 方法本质上是一个有限状态自动机,她通过 while 循环来实现自动运行。那么该状态机何时停止呢?我们就有必要了解一下 isEnd 方法的实现逻辑了。
模板解析的过程
- <div>
- <p>
- Text1
- </p>
- <p>
- Text2
- </p>
- </div>
- div
上面是一个模拟模板解析的简单动画,点击 Next 按钮,可以一步一步解析整个模板字符串,可以看到:
1.当解析器遇到 <div> 时,会开启状态机1,同时向父级节点栈(Ancestors)插入div节点
2.状态机1继续执行,当解析器遇到 <p> 时,会开启状态机2,同时向父级节点栈插入p节点
3.状态机2继续执行,当解析器遇到 </p> 时,检查父节点栈中是否有<p>节点,如果有,说明该标签被解析完成了,结束状态机2
4.状态机1继续执行,当解析器遇到 <p> 时,会开启状态机3,同时向父级节点栈插入p节点
5.状态机3继续执行,当解析器遇到 </p> 时,检查父节点栈中是否有<p>节点,如果有,说明该标签被解析完成了,结束状态机3
6.状态机1继续执行,当解析器遇到 </div> 时,且父节点栈中有<div>节点,整个模板解析完成,结束状态机1
那么我们就可以写出 isEnd 方法的实现代码了:
isEnd 代码
// isEnd 方法接受两个参数
// 第一个参数为上下文对象
// 第二个参数为祖先节点栈
export const isEnd = (context: Context, ancestors: Array<TplAst>): boolean => {
// 如果文本被解析完了,直接返回 true
if (!context.source) {
return true;
}
// 倒序遍历祖先节点栈
for (let i = ancestors.length - 1; i >= 0; --i) {
// 如果当前遇到的闭合标签与祖先节点中的标签匹配,返回true
if (context.source.startsWith(`</${ancestors[i].tag}`)) {
return true;
}
}
return false;
};
解析标签节点
当确定状态机停止的时机之后,我们就可以去实现相应的节点解析方法了,我们先从难度最大的标签解析开始。
我们知道,标签的结构简单说来,就是如下三部分:

我们解析标签,就是解析上面三部分,那么我们可以写出以下代码:
解析标签节点代码
export const parseElement = (context: Context, ancestors: Array<TplAst>) => {
// 解析开始标签
const element = parseTag(context);
// 解析标签中的子节点,递归调用 parseChildren
element.children = parseChildren(context, ancestors);
// 解析结束标签
const isEnd = true;
parseTag(context, isEnd);
};
parseTag
可以看到,解析标签的核心方法就是 `parseTag`,解析标签,就是找到匹配标签的规则,然后再进行解析,下面这段代码为一个常见的标签节点:
<div v-if="foo" id="bar">Hello</div>
一个常见标签节点一般有如下元素:
开始标签:
<div>标签属性:
v-if="foo"、id="bar"结束标签:
</div>自闭合标签:
<image />
那我们就可以画出如下解析流程图:
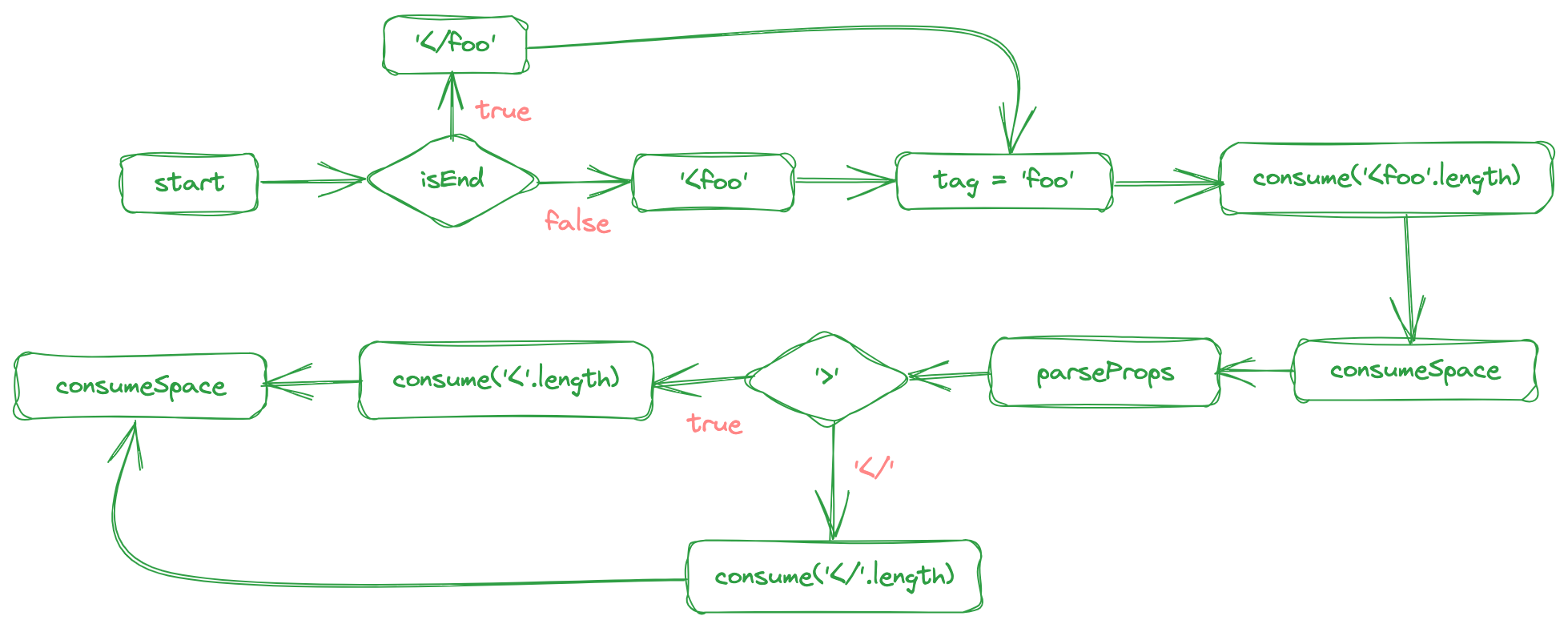
根据上面的流程图,我们可以写出如下解析标签的代码:
parseTag 代码
// 方法接收两个参数
// 第一个参数为上下文对象
// 第二个参数为一个标识,用来判断是否是解析结束标签
export const parseTag = (context: Context, isEnd = false): TplAst | undefined => {
// 从上下文对象中拿出两个消费方法,分别用来消费字符以及空白字符
const { consume, consumeSpace } = context;
// 正则匹配是否是结束标签还是开始标签
const match = isEnd ? /^<\/([a-z][^\t\n\r\f />]*)/i.exec(context.source) : /^<([a-z][^\t\n\r\f />]*)/i.exec(context.source);
if (match) {
// 匹配到的标签名
const tag = match[1];
// match[0].length为匹配到的字符串长度
// 调用消费方法,将解析过的字符串消费掉
consume(match[0].length);
// 消费空白字符,因为可能会出现<p v-if="">foo</p>
consumeSpace();
// 解析属性
const props = parseProps(context);
// 判断是否是自闭合标签
const isSelfClosing = context.source.startsWith('/>');
// 如果是自闭合,消费 '/>',如果不是,消费 '>'
consume(isSelfClosing ? 2 : 1);
// 依旧需要消费空格
consumeSpace();
// 解析完成返回标签的对象
return {
type: TYPE.ELEMENT,
children: [],
props,
tag,
isSelfClosing,
}
}
console.error('不合法的标签');
return undefined;
}
上述代码中提到了两个正则表达式:
/^<\/([a-z][^\t\n\r\f />]*)/i
匹配结束标签,结束标签必须以 </ 开头,且后面要紧跟字符([a-z]),且中间不能有空白字、/ 和 >([^\t\n\r\f />]*)
/^<([a-z][^\t\n\r\f />]*)/i
匹配开始标签,结束标签必须以 < 开头,且后面要紧跟字符([a-z]),且中间不能有空白字、/ 和 >([^\t\n\r\f />]*)
解析属性
在解析标签节点的时候,还要有一个非常重要的解析方法,那就是对于属性的解析,我们先来看看属性的结构:
<div v-if="foo" id=bar v-show='show'></div>
通过上面的代码,我们可以提炼出属性的结构:
属性名:
v-if、id、v-show等号:
=属性值:
foo、bar、show,属性值还分为三种情况:双引号包裹、单引号包裹以及没有引号
根据上面这些结构,我们画一下解析属性的流程图:
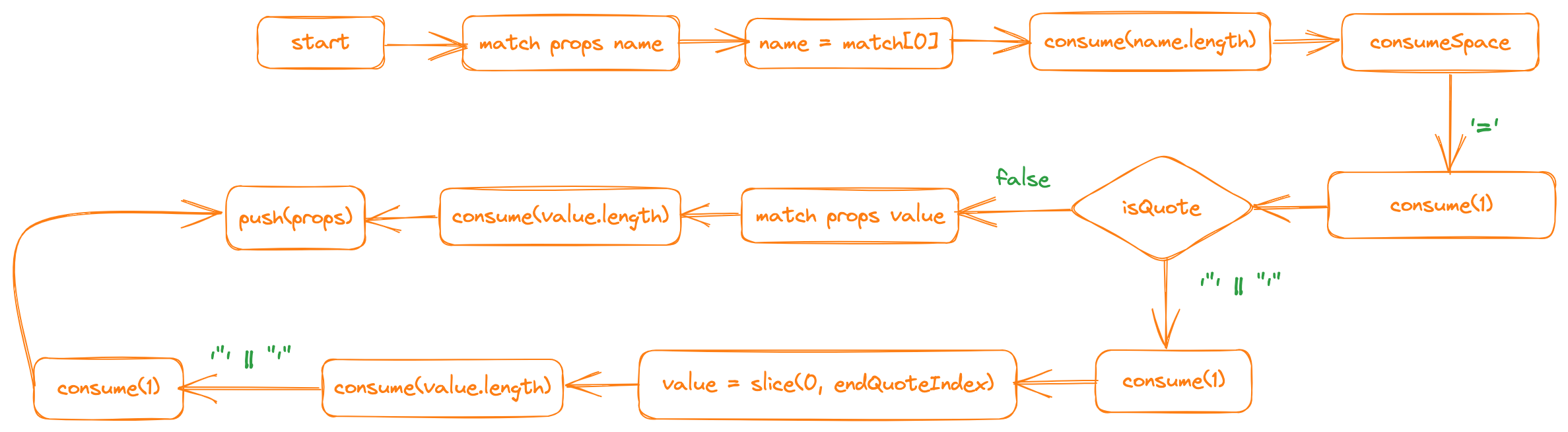
根据上面的流程图,我们就可以写出解析属性的代码了:
解析属性代码
export const parseProps = (context: Context): Array<Props> => {
const { consume, consumeSpace } = context;
// 用来存储属性的数组
const props: Array<Props> = [];
// 属性解析的结束标志
while(!context.source.startsWith('>') && !context.source.startsWith('/>')) {
// 匹配属性名
const matchName = /^[^\t\n\r\f />][^\t\n\r\f />=]*/.exec(context.source);
if (matchName) {
// 获取属性名
const name = matchName[0];
// 消费属性名长度的字符
consume(name.length);
// 消费空白字符
consumeSpace();
// 消费等号
consume(1);
// 消费空白字符
consumeSpace();
// 属性值初始为''
let value = '';
// 判断是否有引号包裹
const quote = context.source[0];
const isQuoted = quote === "'" || quote === '"';
if (isQuoted) {
// 消费引号
consume(1);
// 结束引号的位置
const endQuoteIndex = context.source.indexOf(quote);
if (endQuoteIndex > -1) {
// 当前位置到引号结束位置就是属性值的内容
value = context.source.slice(0, endQuoteIndex);
// 解析完成之后消费属性值长度的字符串
consume(value.length);
// 消费结束引号
consume(1);
} else {
console.error('缺少引号')
}
} else {
// 没有引号的情况下直接匹配属性值
const matchValue = /^[^\t\n\r\f />]+/.exec(context.source);
if (matchValue) {
value = matchValue[0];
consume(value.length);
} else {
console.error('不合法的属性值');
}
}
consumeSpace();
// 解析完成之后将解析完毕的属性添加到属性数组中
props.push({
// 如果属性名以如下字符开头,则可以视为 directive
type: (name.startsWith('v-') || name.startsWith(':') || name.startsWith('@')) ? TYPE.DIRECTIVE : TYPE.ATTRIBUTE,
name,
value,
})
} else {
console.error('不合法的属性名');
}
}
return props;
}
上述代码中提到了两个正则表达式:
/^[^\t\n\r\f />][^\t\n\r\f />=]*/
表达式分为两部分,前面一个 [] 用来匹配一个位置,该位置不能是 空白字符、/ 以及 >,后面一个 [] 用于匹配 0 个或多个位置,这些位置不能是 空白字符,也不能是 /、>、=。注意,这些位置不允许出现 =,这就实现了只匹配等于号之前的内容,即属性名称。
/^[^\t\n\r\f />]+/
该正则表达式从字符串的开始位置进行匹配,并且会匹配一个或多个非空白字符、非字符 >。即:该正则表达式会一直对字符串进行匹配,直到遇到 空白字符 或 > 为止,这就实现了属性值的提取。
完善 parseElement
在前面我们写了一下 `parseElement` 的伪代码。前面我们实现的标签解析、属性解析等都是以一般的标签节点为例,但是标签节点分为多种情况(在前面也介绍过不同的模式),我们接下来还需要考虑其他不同类型的标签节点,比如:
textarea、titlestyle、iframe等
下面是完整的 parseElement 的实现
parseElement 完整代码
export const parseElement = (context: Context, ancestors: Array<TplAst>) => {
// 解析开始标签
const element = parseTag(context);
if (element) {
// 是否为自闭合标签
if (element.isSelfClosing) {
return element;
}
// textarea、title 标签需要切换模式
if (element.tag === 'textarea' || element.tag === 'title') {
context.mode = MODE.RCDATA;
// style等标签也需要切换模式
} else if (element.tag && /style|xmp|iframe|noembed|noframes|noscript/.test(element.tag)) {
context.mode = MODE.RAWTEXT;
} else {
// 解析正常的标签节点
context.mode = MODE.DATA;
}
// 将节点插入栈中
ancestors.push(element);
// 解析子节点
element.children = parseChildren(context, ancestors);
// 出栈
ancestors.pop();
// 解析结束标签
if (context.source.startsWith(`</${element.tag}`)) {
parseTag(context, true);
} else {
console.error(`${element.tag} 标签缺少闭合标签`);
}
}
return element;
}
解析文本
我们先来看看文本节点在模板字符串中的结构:
<div>Text1</div>
<div>Text2 {{ foo }}</div>
文本的解析其实比较简单,我们只需要找到文本的结束位置即可。通过上面的代码我们发现,文本的结束位置有两种情况:
遇到
<遇到
{{
解析文本节点代码
export const parseText = (context: Context): TplAst => {
const { consume } = context;
// 文本结束位置,初始为整个字符串的结束位置
let endIndex = context.source.length;
// 文本解析的结束位置要么是下一个标签的开始,即:遇到'<'
const elementStartIndex = context.source.indexOf('<');
// 要么是插值节点的开始,即:遇到 '{{'
const interpolationIndex = context.source.indexOf('{{');
// 比较两个结束位置,取较小值
if (elementStartIndex > -1 && elementStartIndex < endIndex) {
endIndex = elementStartIndex;
}
if (interpolationIndex > -1 && interpolationIndex < endIndex) {
endIndex = interpolationIndex;
}
// 截取文本
const content = context.source.slice(0, endIndex);
// 消费文本长度的字符
consume(content.length);
return {
type: TYPE.TEXT,
content,
}
}
解析注释
注释的解释也很简单,跟文本类似,我们也只需要确定注释的结束位置即可,注释的结束位置就是结束标识符:-->
解析注释代码
export const parseComment = (context: Context): TplAst => {
const { consume } = context;
// 消费注释开始标识符
consume('<!--'.length);
// 获取注释结束的位置
const closeIndex = context.source.indexOf('-->');
// 不合法的注释
if (closeIndex < 0) {
console.error('缺少注释界定符');
}
// 获取注释内容
const content = context.source.slice(0, closeIndex);
// 消费注释内容
consume(content.length);
// 消费结束标识符
consume('-->'.length);
return {
type: TYPE.COMMENT,
content,
}
}
解析插值
插值的解析和注释比较类似,我们只需要找到插值的结束标识符即可:}},另外插值的内容是表达式,所以插值的 content 我们使用这样的结构来表示:
content: {
type: TYPE.EXPRESSION,
content: string,
}
解析插值
export const parseInterpolation = (context: Context): TplAst => {
const { consume } = context;
// 消费插值开始标识符
consume('{{'.length);
// 获取插值结束位置
const closeIndex = context.source.indexOf('}}');
// 不合法的插值
if (closeIndex < 0) {
console.error('缺少插值界定符');
}
// 截取插值
const content = context.source.slice(0, closeIndex);
// 消费插值内容
consume(content.length);
// 消费插值结束标识符
consume('}}'.length);
// 返回插值节点,插值的内容为表达式,所以这里给了一个新的类型
return {
type: TYPE.INTERPOLATION,
content: {
type: TYPE.EXPRESSION,
content,
}
}
}
那么至此,我们就实现了一个简单的解析器,可以将 <div v-if="foo" id="bar"><p>Text1</p><p>Text2</p></div> 粘贴到下面的文本框中,然后点击 Parse 查看效果
转换器
我们在前面已经实现了解析器,我们知道解析器会将模板代码转换为模板AST,那么下一步,我们就需要对模板AST进一步处理,将其转换为 JavaScript AST,这就需要转换器来实现了:

我们先定义一下 transform 方法:
export const transform = (
ast: TplAst,
plugins: Array<(currentNode: TplAst, context: Context) => any>
) => {
// 定义上下文对象
const context = newContext(plugins);
// 访问节点
traverseNode(ast, context);
}
转换器的核心其实就是对模板AST进行处理,进而将其转换为 JavaScript AST,要想实现对模板AST的处理,我们就需要能访问模板AST中的每一个节点,也就是需要实现上述代码中的 traverseNode,由于模板AST的结构是一颗树,我们可以画出访问模板AST的流程图:
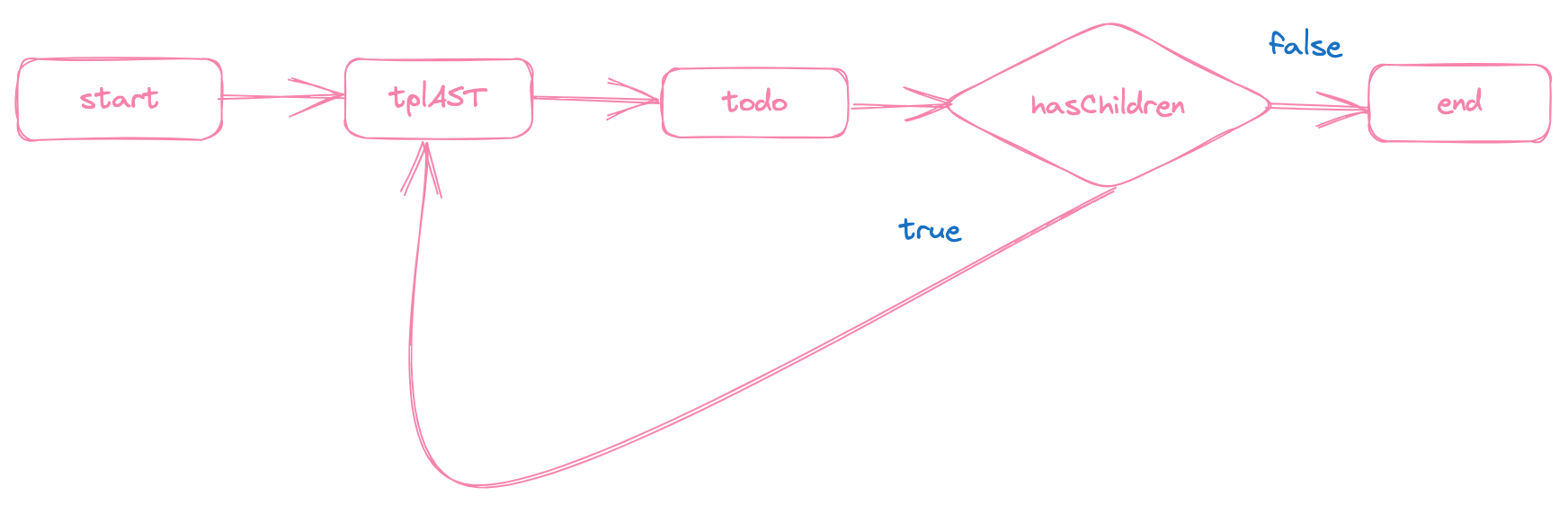
根据上述流程图,我们可以实现 traverseNode:
traverseNode 代码
export const traverseNode = (ast: TplAst) => {
// 当前节点
const currentNode = ast;
// 当前节点的子节点
const children = currentNode.children;
// handle currentNode
//------------------------------------------
const { type, tag } = currentNode;
if (type === TYPE.ELEMENT && tag === "p") {
currentNode.tag = "h1";
}
if (type === TYPE.TEXT) {
currentNode.content = "Morris is an idiot";
}
// more todos can put here
//------------------------------------------
// 递归访问子节点
children && children.forEach((_) => traverseNode(_));
};
插件架构
在上面的代码中,我们在访问节点的时候可能需要写很多处理节点的方法,比如上面代码中实现的替换标签以及替换文本的功能。当然,随着功能不断变得复杂,我们会加入更多的处理方法在 traverseNode 中,这样就会导致 traverseNode 变得非常臃肿,为了解决这个问题,我们可以将处理方法拿出来,通过插件的形式进行处理,在实现插件架构之前,我们先定义上下文对象:
上下文对象数据结构
export class Context {
currentNode: TplAst | null; // 当前访问节点
childIndex: number; // 当前节点在父节点中的索引
parent: TplAst | null; // 当前节点的父节点
plugins: Array<(currentNode: TplAst, context: Context) => any>; // 插件,为一个函数数组
}
有了上下文对象之后,我们就可以将处理节点的方法抽离出来,全部在上下文对象中存储:
重新实现的 traverseNode 代码
export const traverseNode = (ast: TplAst, context: Context) => {
// 在上下文对象中维护当前节点
context.currentNode = ast;
// 取出上下文对象中的插件方法
const plugins = context.plugins;
// 遍历执行
plugins.forEach((fn) => fn(ast, context))
// 获取子节点
const children = context.currentNode.children;
if (children) {
children.forEach((item: TplAst, index: number) => {
context.parent = context.currentNode;
context.childIndex = index;
// 递归处理子节点
traverseNode(item, context);
})
}
}
节点的进入与退出
在处理节点的时候,我们有时候需要等待子节点处理完成之后才去处理父节点,但是我们目前设计的转换工作流是无法实现这一点的,如下图所示:

我们现在的工作流在处理某个子节点的时候,其父节点就已经被处理完了,我们再也无法回头去处理父节点了。为了解决这样的问题,我们需要如下的工作流:
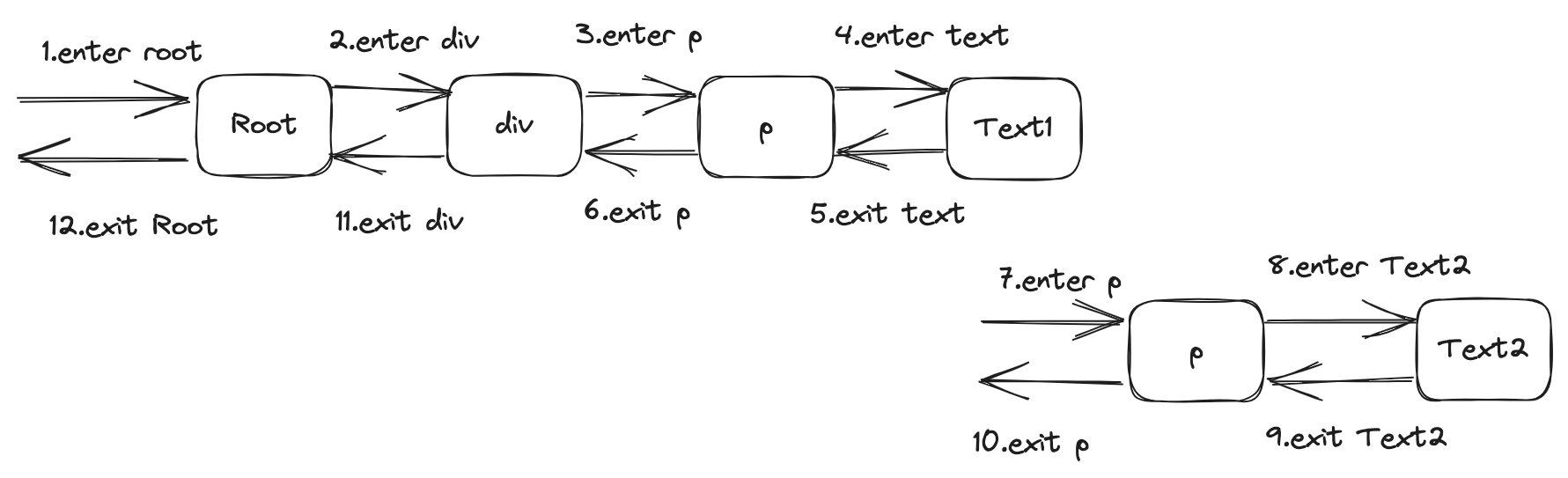
通过上图我们可以看到,这种工作流对节点的访问分为两个阶段:进入阶段和退出阶段。
- 进入阶段:先进入父节点,再进入子节点
- 退出阶段:先退出子节点,再退出父节点
那我们重新实现 traverseNode:
重新实现过的 traverseNode
export const traverseNode = (ast: TplAst, context: Context) => {
// 上下文对象中维护当前节点
context.currentNode = ast;
// 定义一个数组,用来缓存退出方法
const exitFns: Array<() => any> = [];
// 获取插件方法
const plugins = context.plugins;
plugins.forEach((fn) => {
// 转换函数可以返回另外一个函数,该函数即作为退出阶段的回调函数
const onExit = fn(ast, context);
if (onExit) {
// 将退出阶段的回调函数添加到 exitFns 数组中
exitFns.push(onExit);
}
});
const children = context.currentNode.children;
if (children) {
children.forEach((item: TplAst, index: number) => {
context.parent = context.currentNode;
context.childIndex = index;
traverseNode(item, context);
});
}
// 反序执行缓存在 exitFns 中的方法
let i = exitFns.length;
while (i--) {
exitFns[i]();
}
};
// 一个转换函数的例子,该函数会返回另一个函数
export const handleText = (node: TplAst, context: Context) => {
return () => {
const { type } = node;
if (type === TYPE.TEXT) {
node.content = "Morris is an idiot";
}
};
};
那我们就已经实现好了节点访问的方法,有了该方法,那么接下来我们任务就是去实现将模板AST节点转换为 Javascript AST 节点的方法。
Javascript AST
在实现转换方法之前,我们需要先了解一下转换后的 JavaScript AST 的结构。我们知道 JavaScript AST 也是一个中间代码,编译器最终会根据她来生成目标代码,也就是如下所示的渲染函数:
function render() {
return h("div", [h("p", "Text1"), h("p", "Text2")]);
}
上面就是最终所要生成的渲染函数,那么我们怎么去描述这个函数呢?我们先将该函数体进行解构:
函数声明:
function函数签名:
render函数体:
{...}return语句:
h("div", [h("p", "Text1"), h("p", "Text2")])return语句的值为函数调用:
h(...)函数的参数:
"div", [h("p", "Text1"), h("p", "Text2")
通过上面这些元素,我们就可以这样去描述 render 方法:
用 Javascript AST 描述 render 函数
{
"type": "FUNC",
"value": "render",
"body": [
{
"type": "RETURN",
"returnExpress": {
"type": "CALL",
"value": "h",
"arguments":[
{ "type":"STRING", "value":"div" },
{ "type":"ARRAY", "elements":
[
{
"type":"CALL", "value":"h", "arguments":
[
{ "type":"STRING", "value":"p" },{ "type":"STRING", "value":"Text1" }
]
},
{
"type": "CALL", "value": "h", "arguments":
[
{ "type":"STRING", "value":"p" },{ "type":"STRING", "value":"Text2" }
]
}
]
}
]
}
}
]
}
通过上面的结构,我们可以写出 JavaScript AST 的数据结构:
interface JsAst
export enum TYPE {
FUNC = 'FUNC', // 函数声明
STRING = 'STRING', // 文本
ARRAY = "ARRAY", // 数组
CALL = 'CALL', // 函数调用
RETURN = 'RETURN', // return 语句
}
export interface JsAst {
type: TYPE,
value?: string, // 值,用来描述函数名称等
params?: Array<JsAst>, // 声明函数的参数
body?: Array<JsAst>, // 函数体
arguments?: Array<JsAst>, // 调用函数的传参
elements?: Array<JsAst>, // 数组的元素
returnExpress?: JsAst, // return 表达式
}
jsNode
在前面介绍解析器的时候,我们定义了模板AST的数据结构,在该数据结构中有一个属性:jsNode,该属性就是用来描述该节点的 JavaScript AST,我们在对节点进行 Javascript AST 转换时,转换结果就存储在 jsNode 属性上面。
模板AST数据结构
export interface TplAst {
type: TYPE,
tag?: string,
isSelfClosing?: boolean,
props?: Array<Props>,
content?: string | Content,
children?: Array<TplAst>,
jsNode?: JsAst,
}
为了更好地对模板AST进行转换,我们将两种语法树放在一起进行比较:
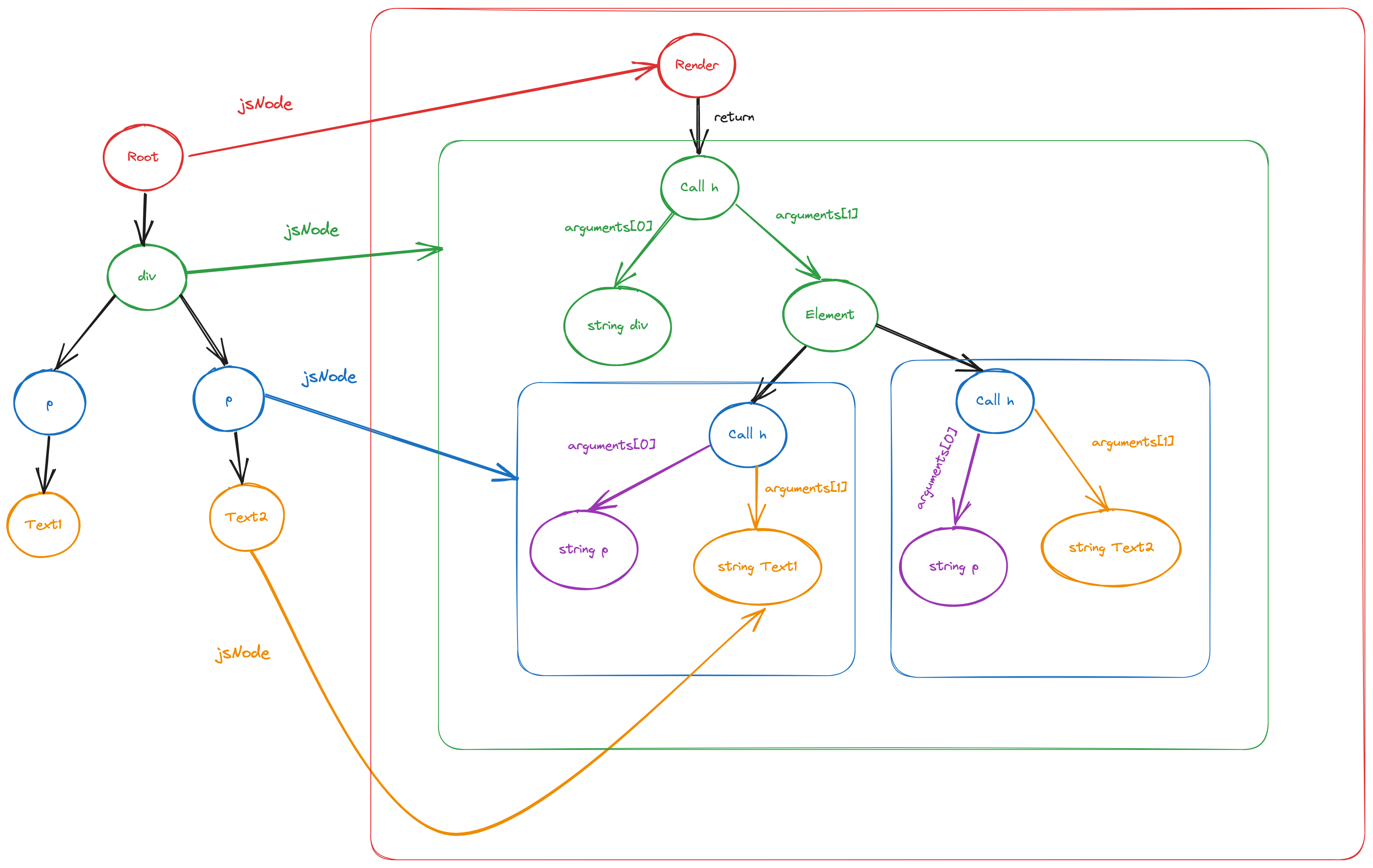
可以发现如下关系:
根节点会被转换为 render 函数
模板AST中的标签节点会被转换为
h方法的调用,该方法的第二个参数为子节点的jsNode
工具方法
在具体实现转换方法之前,我们先写几个工具方法,方便后续转换时使用:
tool functions
// 创建文本
export const newString = (value?: string): JsAst => ({
type: TYPE.STRING,
value,
});
// 创建数组
export const newArray = (elements?: Array<JsAst>): JsAst => ({
type: TYPE.ARRAY,
elements,
});
// 创建 call
export const newCall = (value?: string, args?: Array<JsAst>): JsAst => ({
type: TYPE.CALL,
value,
arguments: args,
});
// 创建 return 表达式
export const newReturn = (returnExpress?: JsAst): JsAst => ({
type: TYPE.RETURN,
returnExpress,
});
// 创建函数声明
export const newFunc = (value: string, body: Array<JsAst>, params?: Array<JsAst>) => ({
type: TYPE.FUNC,
body,
value,
params,
});
转换文本
文本的转换比较简单,直接调用工具方法 newString 即可
transformText
export const transformText = (node: TplAst, context: Context) => {
if (node.type == TPL_AST_TYPE.TEXT) {
// 直接调用 newString
node.jsNode = newString(node.content as string | undefined);
}
}
转换标签节点
通过上面的分析我们知道:模板AST中的标签节点会被转换为 h方法 的调用,该方法的第二个参数为子节点的 jsNode
transformElement
export const transformElement = (node: TplAst, context: Context) => {
return () => {
if (node.type === TPL_AST_TYPE.ELEMENT) {
// h 方法的第一个参数,比如:h('div')
const callExp = newCall('h', [newString(node.tag)]);
if (node.children) {
if (node.children.length === 1) {
// 如果子节点数量等于1,h 方法的第二个参数为子节点的jsNode
if (node.children[0] && node.children[0].jsNode) {
callExp.arguments ? callExp.arguments.push(node.children[0].jsNode) : callExp.arguments = [node.children[0].jsNode];
}
} else {
// 如果子节点数量大于1,h 方法的第二个参数为子节点的jsNode集合
const args = node.children.map(item => item.jsNode).filter(_ => _) as Array<JsAst>;
callExp.arguments ? callExp.arguments.push(newArray(args)) : callExp.arguments = [newArray(args)];
}
}
node.jsNode = callExp;
}
}
}
转换根节点
根节点的转换也非常简单,根节点会被转换为 render 方法的声明
transRender
export const transRender = (node: TplAst, context: Context) => {
return () => {
if (node.type === TPL_AST_TYPE.ROOT) {
if (node.children) {
// 获取子节点的jsNode
const jsAst = node.children[0].jsNode;
// 方法体位 return 语句
const body = newReturn(jsAst);
node.jsNode = newFunc('render', [body])
}
}
}
}
那么至此,我们就实现了一个简单的转换器,可以将 <div><p>Text1</p><p>Text2</p></div> 粘贴到下面的文本框中,然后点击 Transform 查看效果
生成目标代码
前面我们通过转换器将模板AST转换为了 JavaScript AST,那么我们最后一步就是将 JavaScript AST 转换为目标代码,如下图所示:
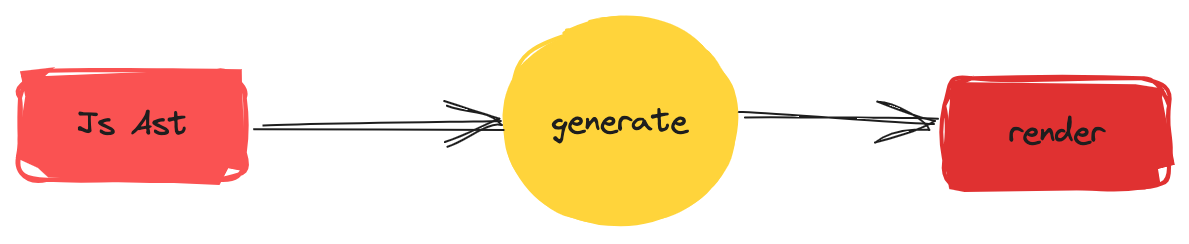
其实将 JavaScript AST 转换为 目标代码 本质上就是:字符串拼接的艺术
定义上下文对象
在开始生成代码之前,我们还是先定义一下上下文对象
interface Context
export class Context {
code: string; // 生成的代码
currentIndent: number; // 当前缩进
constructor(code: string, currentIndent: number) {
this.code = code;
this.currentIndent = currentIndent;
}
// 拼接字符串
push = (code: string) => {
this.code += code;
}
// 换行
newLine = () => {
this.code += '\n' + ' '.repeat(this.currentIndent);
}
// 缩进
indent = () => {
this.currentIndent++;
this.newLine();
}
// 取消缩进
deIndent = () => {
this.currentIndent--;
this.newLine();
}
}
实现 generate 方法
在上面我们定义了上下文对象,那么接下来我们先实现 generate 方法:
export const generate = (node: JsAst): string => {
const context = newContext();
geneNode(node, context);
return context.code;
}
可以看到,generate 方法的核心其实就是 geneNode,那么怎么实现 geneNode,我们先画一下生成代码的流程图,这里只画了函数声明和文本生成的流程图:
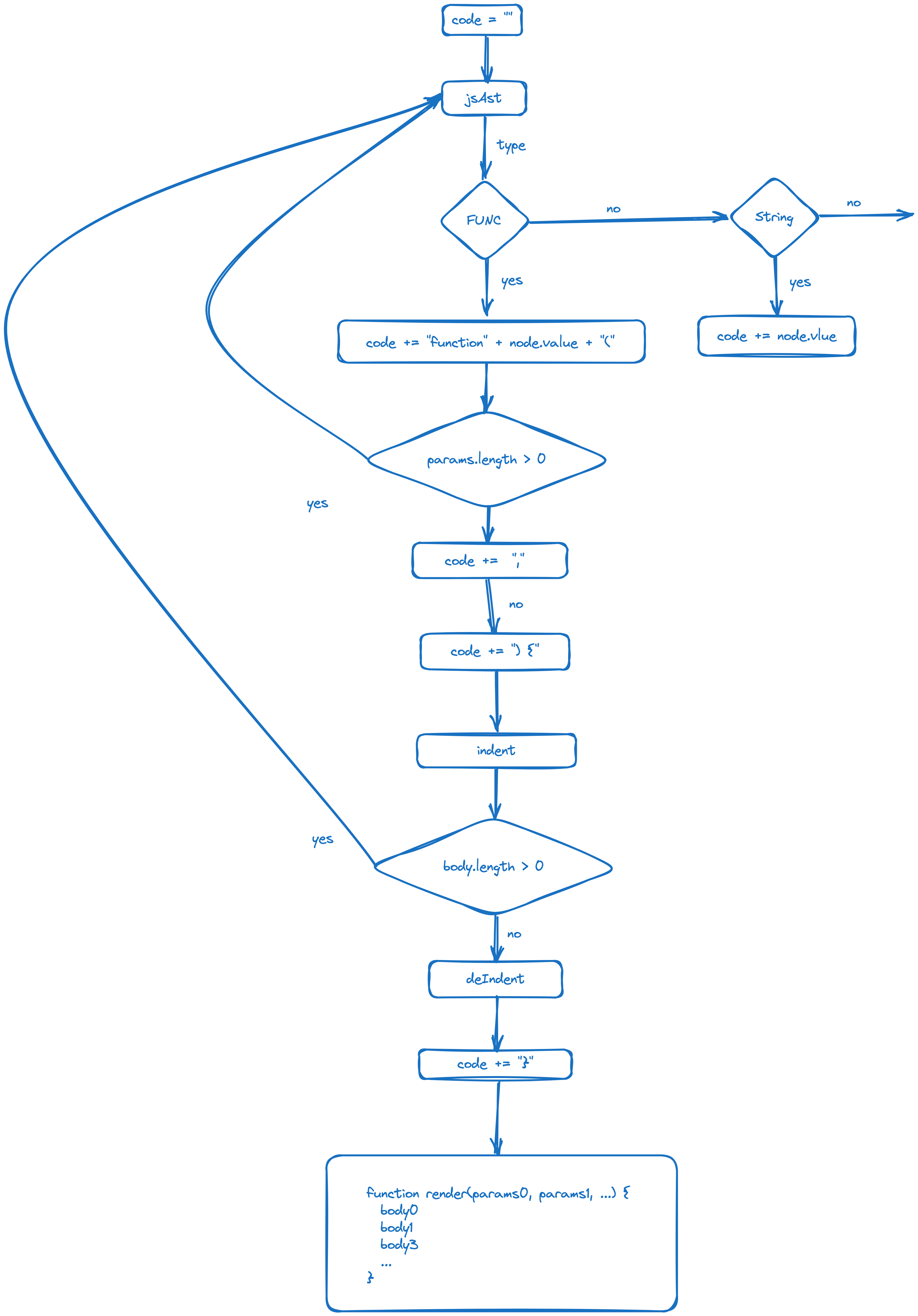
通过该流程图,我们实现 geneNode 方法如下:
geneNode 代码
export const geneNode = (node: JsAst, context: Context) => {
switch(node.type) {
// 函数声明
case TYPE.FUNC: geneFuc(node, context); break;
// return 语句
case TYPE.RETURN: geneReturn(node, context); break;
// 函数调用语句
case TYPE.CALL: geneCall(node, context); break;
// 文本
case TYPE.STRING: geneString(node, context); break;
// 数组
case TYPE.ARRAY: geneArray(node, context); break;
}
};
我们的核心就是去实现上面列举的一些方法,再实现具体方法之前,先实现一个工具方法,用来拼接数组:
geneNodeList
// 接受两个参数
// 第一个参数为数组,第二个为上下文对象
const geneNodeList = (nodes: Array<JsAst>, context: Context) => {
const { push } = context;
nodes.forEach((n: JsAst, index: number) => {
// 循环调用geneNode
geneNode(n, context);
if (index < nodes.length - 1) {
// 如果不是最后一个节点,添加 ','
push(', ');
}
})
}
生成函数声明代码
geneFuc
const geneFuc = (node: JsAst, context: Context) => {
const { push, indent, deIndent } = context;
// 拼接函数声明
push(`function ${node.value}(`);
// 拼接参数
if (node.params) {
geneNodeList(node.params, context);
}
push(') {');
// 缩进
indent();
if (node.body) {
// 递归调用geneNode生成方法体
node.body.forEach((b: JsAst) => geneNode(b, context));
}
// 消除缩进
deIndent();
push('}')
};
生成函数调用代码
geneCall
const geneCall = (node: JsAst, context: Context) => {
const { push } = context;
const { value, arguments: args } = node;
if (value) {
// 函数签名
push(`${value}(`);
if (args) {
// 函数调用的参数
geneNodeList(args, context);
}
push(')');
}
}
生成 return 表达式
geneReturn
const geneReturn = (node: JsAst, context: Context) => {
const { push } = context;
push('return ');
if (node.returnExpress) {
geneNode(node.returnExpress, context);
}
}
生成数组
geneArray
const geneArray = (node: JsAst, context: Context) => {
const { push } = context;
push('[')
if (node.elements) {
geneNodeList(node.elements, context);
}
push(']')
}
生成文本
geneString
const geneString = (node: JsAst, context: Context) => {
const { push } = context;
push(`'${node.value}'`);
}
那么到此我们的编译器就已经实现了,可以将 <div><p>Text1</p><p>Text2</p></div> 粘贴到下面的文本框中,然后点击 Compile 查看效果:
最后
本文其实只是对编译器粗浅地讲了一下,实际上 Vue 的编译器比这个要复杂很多。本文为了讲清楚大致的流程和原理省略了很多细节,如果要更进一步了解可以看看 Vue 的源码以及社区其他优秀的文章。本篇文章中的例子,请戳